WebScraper 4.15.4 已通过小编安装运行测试 100%可以使用。
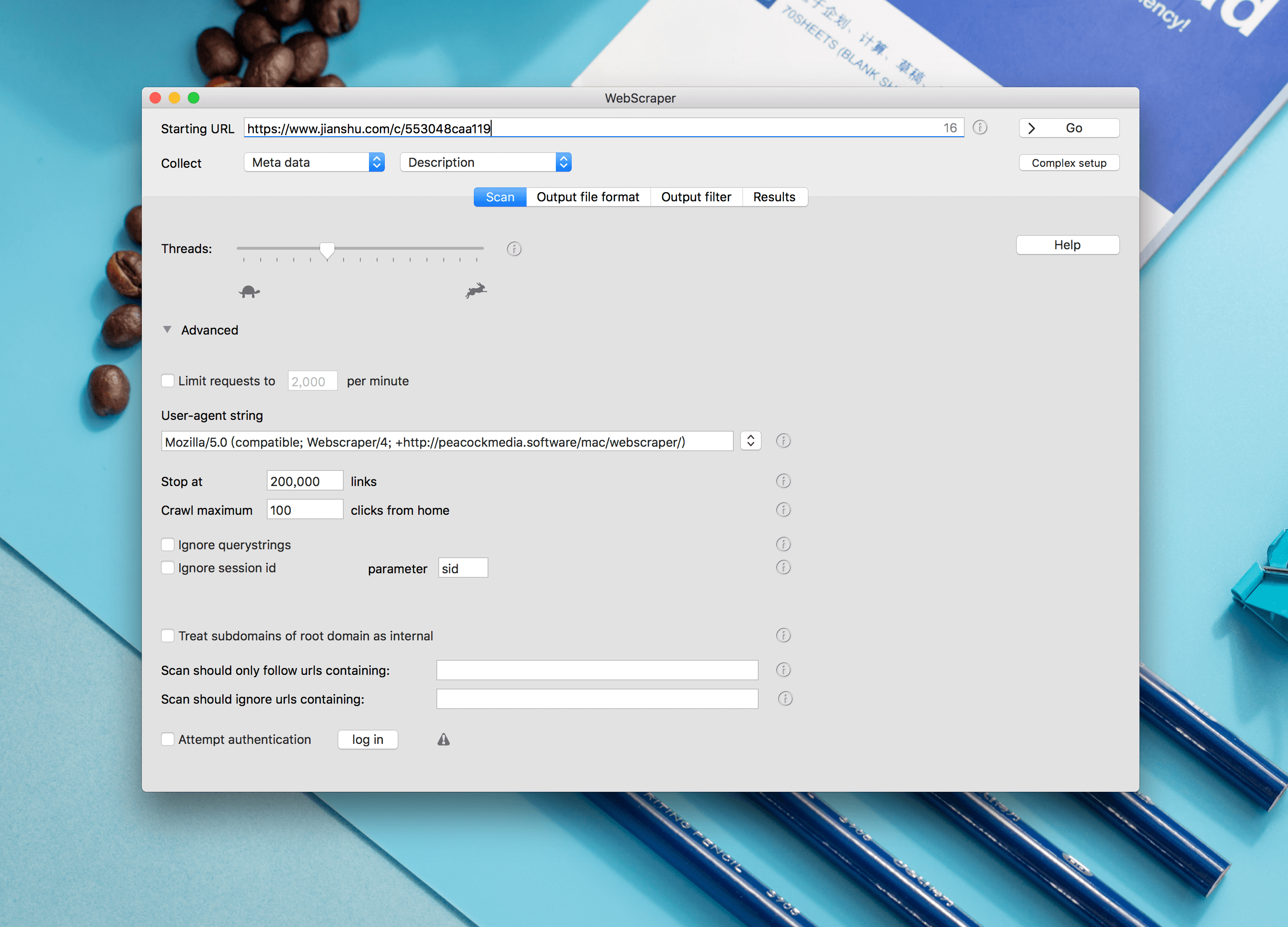
WebScraper 4.15.4 可以从网站上抓取数据并保存数据。只需输入目标网址,WebScraper即可快速轻松地扫描抓取网站数据,并将数据保存为csv或json格式。
WebScraper 的功能特性
可以通过ProxyCrawl服务为每个请求使用不同的IP,用户代理等
支持macOS系统
有多种提取数据的方法;各种元数据,内容(如文本,html或markdown),具有某些类/ id的元素,正则表达式
易于导出数据-选择所需的列
将数据输出为csv或json
选择将所有图像下载到文件夹/收集和导出所有链接的选项
输出单个文本文件的选项(设计用于归档文本内容,markdown或纯文本)
大量的选项/配置
WebScraper 4.15.4的新功能:
解决超时问题:在“高级扫描设置”下添加超时控制,如果遇到超时,请务必使用线程滑块或“将请求限制为每分钟X个”来限制抓取数量。这通常可以解决超时问题。


声明:本站所有资源,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![AI绘画软件stable diffusion国风novelai绘图软件中文Win/Mac苹果[共830G]](https://youzhan-cdn.oss-cn-beijing.aliyuncs.com/2023/04/20230428015812391.jpeg)