
哈喽O(∩_∩)O
今天来发一下python正则表达式,其实这个也是比较简单的
肝了好几个小时才写出来呀
什么是正则表达式(⊙_⊙)
目前越来越多的网站、编辑器、编程语言都已支持一种叫“正则表达式”的字符串查找“公式”,有过编程经验的同学都应该了解正则表达式(Regular Expression 简写regex)是什么东西,它是一种字符串匹配的模式(pattern),更像是一种逻辑公式。
简单说,正则表达式是…
python中必备的工具,主要是用来查找和匹配字符串的。
正则表达式尤其在python爬虫上用的多。
正则表达式怎么用❓
首先,我们要导入头文件(写c++写习惯了)模块
import re因为re是内置模块,所以不需要额外安装,就很银杏
sreach的用法????
匹配连续的多个数值????

re模块中,r“\d+”正则表达式表示匹配连续的多个数值,search是re中的函数,从”YRYR567eruwgf”字符串中搜索连续的数值,得到”567″
结果:
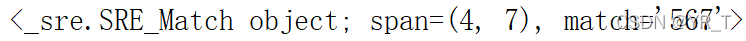
可以看到,搜索到了连续值“567”
字符”+”重复前面一个匹配字符一次或者多次????

这样,结果就是b后面的连续数字
结果:

字符”*”重复前面一个匹配字符零次或者多次????
“*” 与 “+”类似,但有区别,列如:
可见 r”ab+“匹配的是”ab”,但是r”ab “匹配的是”a”,因为表示”b”可以重复零次,但是”+“却要求”b”重复一次以上

结果:

字符”?”重复前面一个匹配字符零次或者一次????
匹配结果”ab”,重复b一次

结果:

特殊字符使用反斜杠”“引导,例如”\r”、”\n”、”\t”、”\”分别表示回车、换行、制表符号与反斜线自己本身

结果:

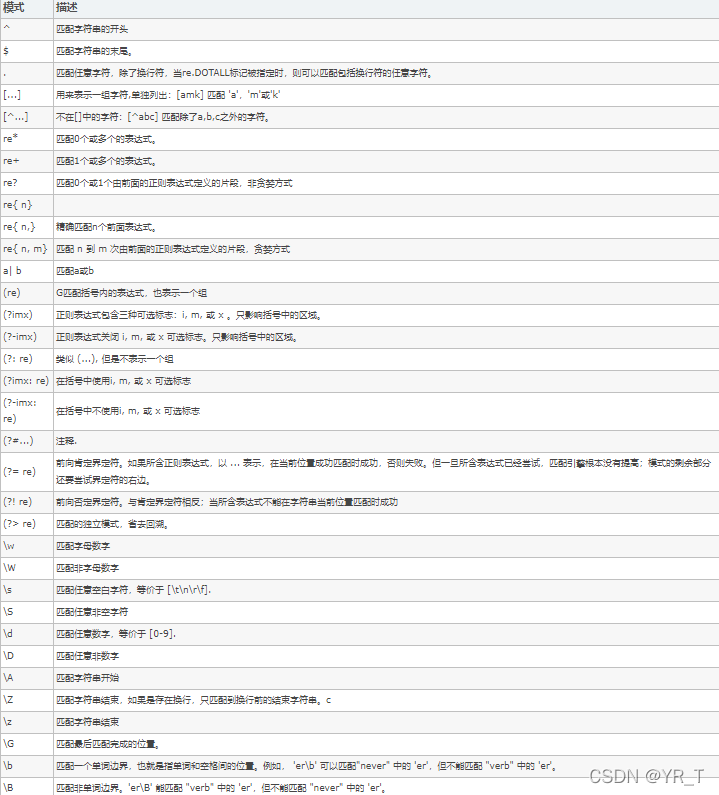
完整表
其实上面说这些都是比较基础,比较简单的,还有复杂一点的,都在这张表里
match用法
match用法
语法:re.match(pattern, string[, flags])
从首字母开始开始匹配,string如果包含pattern子串,则匹配成功,返回Match对象,失败则返回None,若要完全匹配,pattern要以$结尾。
输出结果:张三,你好

张三:谁叫我?
不开玩笑了,继续
总的来说,match就是
- 返回匹配的match对象
- 默认从给定字符串的开头开始匹配、即使正则表达式没有用^声明匹配开头
match对象
Match对象的几个属性:
注意,前面是有“.”的
1..string 待匹配的文本
2..re 匹配使用的pattern对象
3..pos 正则表达式搜索文本的开始位置
4..endpos 正则表达式搜索文本的结束位置
Match对象的几个方法:
1.group(0) 返回匹配到的子串
2.start() 返回匹配子串的开始位置
3.end() 返回匹配子串的结束位置
4.span() 返回start()、end()
数量词

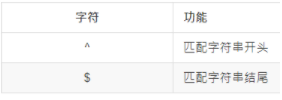
匹配开头、结尾
匹配分组

好了,看了上面几张表,其实我觉得最重要的在下面
match总结
其实没啥好总结的,但你要看懂这张图,这个很重要
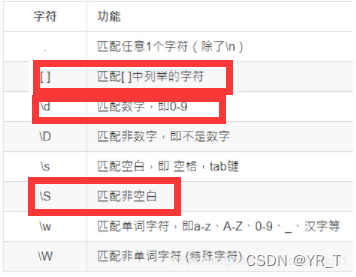
我框出来的是我自己感觉经常用的
其实我自己刚学的时候也听不懂,现在觉得可简单了
所以,你应该现在就觉得很简单吧?
但是,正则表达式的字符很多,容易记混,一不小心就好几十个报错,很让人崩溃

实践出真知 凸(`0´)凸 ☀️
学了这么多,是不是想撸个程序了?
已经给你准备好了
程序效果:输入手机号,通过正则表达式判断手机号合不合法,
如果合法,就输出这个手机号的信息(所属地等)
如果不合法,就重新输入,简单吧?
这里我想重点说一下怎么获取手机号的信息
我一开始打算上网上百度一波的,没想到直接复制过来23个报错、我也是醉了

哎呀,不能再发表情包了

ε=(´ο`*)))唉,还是自己写吧、、、
我想起了有个模块叫phone,可以实现这个功能
但是你可能还没有安装这个模块,要按命令行模式下输入pip install phone
等个六六四十九秒就下载下来了
然后你就可以体验一下了
代码(PyCharm运行通过)
.png)
写在最后
感觉这次的博客好像比较长,你能看到这里,已经超越了60%的人了,如果有谁还不是很明白,或者有c++和python的问题,都可以私信我,我看到后会一一回复哦

![12个例⼦带你⼊门Electron[8000字附源码]](https://www.jwee.net/wp-content/themes/ripro-v2/assets/img/thumb.jpg)